15.5. Monte Carlo Uncertainty Analysis for Nonlinear Regression#
Further Reading: §4.12
15.5.1. Learning Objectives#
After studying this notebook, attending class, asking questions, and reviewing your notes, you should be able to:
Use simulation to calculate and analyze probabilities.
Write code to simulate data, add noise, and visually inspect the distribution of fitted parameters through Monte Carlo Uncertainty Analysis.
# load libraries
import scipy.stats as stats
import numpy as np
import scipy.optimize as optimize
import math
import matplotlib.pyplot as plt
15.5.2. Simulation#
See this notebook for notes on simulating a problem to calculate probability, mean, variance, and to determine if a population is normal.
15.5.3. Motivating Example: Cart + Incline#
See this notebook to look at a motivating example for Monte Carlo Error Propogation.
15.5.4. Motivating Example: Michaelis-Menten Enzymatic Reaction Kinetics#
The Michaelis-Menten equation is an extremely popular model to describe the rate of enzymatic reactions.
Additional information: https://en.wikipedia.org/wiki/Michaelis–Menten_kinetics
## Create dataset
# Define exact coefficients
Vmaxexact=2;
Kmexact=5;
# Evaluate model
Sexp = np.array([.3, .4, 0.5, 1, 2, 4, 8, 16]);
rexp = Vmaxexact*Sexp / (Kmexact+Sexp);
# Add some random error to simulate
rexp += 0.05*np.random.normal(size=len(Sexp))
# Evaluate model to plot smooth curve
S = np.linspace(np.min(Sexp),np.max(Sexp),100)
r = Vmaxexact*S / (Kmexact+S)
15.5.5. Main Idea#
Use residuals to estimate uncertainty in dependent variable
Simulate regression procedure 1000s of times, adding random noise to dependent variable
Examine distribution of fitted values
# variance of residuals
print(sigre)
0.003717977540144133
15.5.6. Pseudocode#
Class Activity
Write pseudocode with a partner.
15.5.7. Python Hints#
Let’s say we want to generate a vector with 5 elements, each normally distributed with mean 0 and standard deviation 2. We can do this in one line using Python:
my_vec = np.random.normal(loc = 0,scale = 2,size=(5))
print(my_vec)
[-2.71241136 0.91627376 -0.96646476 2.57309647 0.73030355]
15.5.8. Implement in Python#
Class Activity
Implement your pseudocode in Python.
# Number of Monte Carlo samples
nmc = 1000;
# Number of data points
n = len(rexp)
# Declare a matrix to save the fitted parameters
theta_mc = np.zeros((nmc,2))
# Recall, the standard deviation of the residuals is sigre**0.5
# Perform Monte Carlo simulation
# Add your solution here
15.5.9. Visualize Distribution of Fitted Parameters#
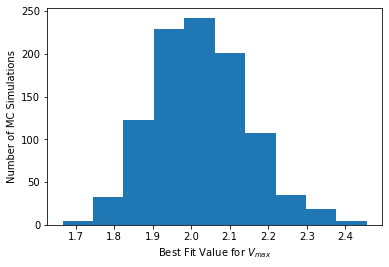
# Histogram for Vmax
plt.hist(theta_mc[:,0])
plt.xlabel("Best Fit Value for $V_{max}$")
plt.ylabel("Number of MC Simulations")
plt.show()
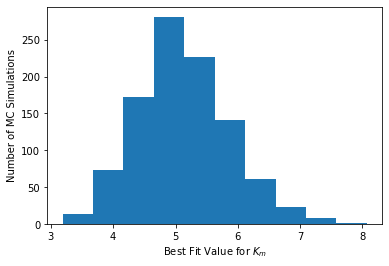
# Histogram for Km
plt.hist(theta_mc[:,1])
plt.xlabel("Best Fit Value for $K_{m}$")
plt.ylabel("Number of MC Simulations")
plt.show()
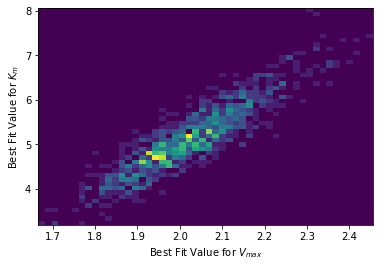
# We can even make a 2D histogram
plt.hist2d(theta_mc[:,0], theta_mc[:,1],bins=50)
plt.xlabel("Best Fit Value for $V_{max}$")
plt.ylabel("Best Fit Value for $K_{m}$")
plt.show()
15.5.10. Compute Covariance Matrix#
## We can calculate covariance in one, carefully constructed line
# For some reason, the NumPy developers choose to assume each ROW is a new variable
# and each COLUMN is a different observation. I would have choose a flipped convention.
# Our 'theta_mc' has each row as a different observation (simulation).
# 'rowvar=False' tells NumPy to flip its convention. This is a great example of
# WHY YOU SHOULD ALWAYS CHECK THE DOCUMENTATION!!!
np.cov(theta_mc,rowvar=False)
array([[0.01497054, 0.08128554],
[0.08128554, 0.54461604]])