14.3. Ordinary Least Squares Linear Regression#
Further Reading: §7.1 and §7.2 in Navidi (2015)
14.3.1. Learning Objectives#
After studying this notebook and your lecture notes, you should be able to:
Interpret correlation coefficient
Compute simple linear regression best fits
# load libraries
import scipy.stats as stats
import numpy as np
import math
import matplotlib.pyplot as plt
Home Activity
Review Chapter 7 in Navidi (2015).
14.3.2. Motivating Example for Linear Regression#
What job responsibilities do you think a chemical engineer would have in the agriculture industry?
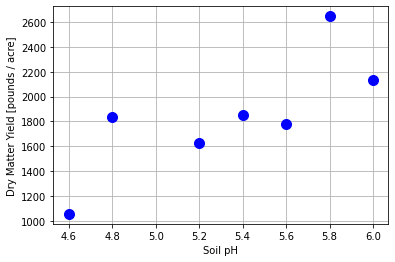
A fellow scientist in Big Ag, Inc. planted alfalfa on several plots of land, identical except for the soil pH. The following are the dry matter yields (in pounds per acre) for each plot.
pH = np.array([4.6, 4.8, 5.2, 5.4, 5.6, 5.8, 6.0])
yld = np.array([1056, 1833, 1629, 1852, 1783, 2647, 2131])
plt.plot(pH,yld,'b.',markersize=20)
plt.xlabel('Soil pH')
plt.ylabel('Dry Matter Yield [pounds / acre]')
plt.grid(True)
plt.show()
Your colleague would like help analyzing these data. In particular:
Is the trend in the data linear?
Can we create a model to predict the dry matter yield based on soil pH?
How can we incorporate uncertainty into our model?
We will use this example throughout the lecture to introduce the fundamentals of linear regression.
14.3.3. Linear Regression Basics#
Based on the plot above, your colleague suggests a simple linear model:
Nomenclature:
\(y\) is the yield (dependent variable, response, observed variable)
\(x\) is the pH (independent variable, feature, manipulated variable)
\(\beta_0\) is the intercept
\(\beta_1\) is the slope
\(\epsilon\) is the random observation error. More on it latter.
We cannot measure \(\beta_0\) and \(\beta_1\) directly. Instead, we can take paired measurements (\(x_1, y_1\)), (\(x_2, y_2\)),… (\(x_n, y_n\)) and find the values of \(\hat{\beta}_0\) and \(\hat{\beta}_1\) that cause the predictions \(\hat{y}\) to best fit the data.
Nomenclature:
\(\hat{y}\) predicted response
\(\hat{\beta}_0\) best fit intercept, estimates true (unknown) intercept
\(\hat{\beta}_1\) best fit slope, estimates true (unknown) intercept
Main idea: \(\hat{\beta}_0\) and \(\hat{\beta}_1\) are estimates of the true (but unknown) intercept and slope.
14.3.4. Optimization Formulation#
At the heart of regression, we want to solve a least-squares minimization problem:
We have done this in multiple lectures already.
14.3.5. Analytic Solution#
Because our model is linear, it is not that difficult to find the analytic solution to the above optimization problem.
Here \(\bar{x}\) and \(\bar{y}\) are the average (mean) values of the independent and dependent variables, respectively, calculated using the sample.
Class Activity
Discuss the following with your neighbor:
How can you calculate the numerator and denominator in a single line using linear algebra?
True/False. The best fit line always passes through (\(\bar{x},\bar{y}\)). Write a sentence to justify your answer.
x = pH
y = yld
n_farm = len(x)
# calculate averages
xbar = np.mean(x)
ybar = np.mean(y)
# calculate numerator
# num = # fill in
num = (x - xbar).dot(y - ybar)
# calculate denominator
# denom = # fill in
denom = (x - xbar).dot(x-xbar)
# calculate slope
b1 = num / denom
# calculate intercept
b0 = ybar - b1 * xbar
# print results
print("slope = ",b1,"pounds per acre / pH unit")
print("intercept =",b0,"pounds per acre")
slope = 737.1014492753624 pounds per acre / pH unit
intercept = -2090.942028985508 pounds per acre
14.3.6. Scipy Package#
We can do the same calculations with Scipy.
b1_, b0_, r_value, p_value, std_err = stats.linregress(x, y)
print("slope = ",b1_,"pounds per acre / pH unit")
print("intercept =",b0_,"pounds per acre")
slope = 737.1014492753623 pounds per acre / pH unit
intercept = -2090.9420289855075 pounds per acre
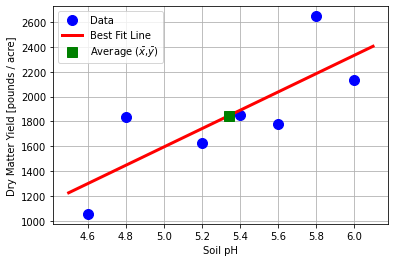
14.3.7. Visualize#
# generate predictions
pH_pred = np.linspace(4.5, 6.1, 20)
yld_pred = b0_ + b1_ * pH_pred
# create plot
plt.plot(pH,yld,'.b',markersize=20,label='Data')
plt.plot(pH_pred,yld_pred,'-r',linewidth=3,label='Best Fit Line')
plt.plot(xbar,ybar,'sg',markersize=10,label=r"Average ($\bar{x}$,$\bar{y}$)")
plt.xlabel('Soil pH')
plt.ylabel('Dry Matter Yield [pounds / acre]')
plt.grid(True)
plt.legend()
plt.show()