14.2. Simple Least Squares#
Further Reading: §7.2 Navidi (2015)
14.2.1. Learning Objectives#
After studying this notebook and your lecture notes, you should be able to:
Understand how to calculate a best fit line numerically or analytically.
Implement scipy to calculate a line of best fit.
Know when the least squares line is applicable.
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
14.2.2. Introduction#
variable |
symbol |
|---|---|
dependent variable |
\(y_i\) |
independent variable |
\(x_i\) |
regression coefficients |
\(\beta_0\) , \(\beta_1\) |
random error |
\varepsilon_i$ |
Linear model:
We measure many \((x_i,y_i\) pairs in lab.
Can we compute \(\beta_0\) , \(\beta_1\) exactly? Why or why not?
Best fit line:
where \(\hat{y}\) is the predicted response and \(\beta_0\) , \(\beta_1\) are the fitted coefficients.
14.2.3. Computing Best Fit Line#
Notice inside the parenthesis we have the sum of the error squared.
We can compute \(\beta_0\) , \(\beta_1\) either numerically or analytically. See the textbook for the full derivation.
Scipy also computes best fit as we will see in the example below.
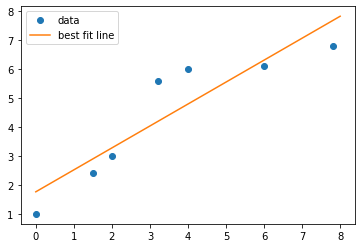
# create data
xdata = [0,1.5,2,3.2,4,6,7.8]
ydata = [1,2.4,3,5.6,6,6.1,6.8]
# use scipy.stats.linregress to calculate a line of best fit and extract the key info
slope, intercept, r, p, se = stats.linregress(xdata,ydata)
# create a lambda function to plot the line of best fit
xline = np.linspace(0,8,10)
y = lambda x: slope*x + intercept
yline = y(xline)
# plot data
plt.plot(xdata,ydata,'o',label="data")
plt.plot(xline,yline,'-',label="best fit line")
plt.legend()
plt.show()
14.2.4. Warnings:#
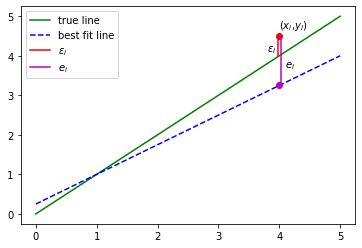
Estimates \(\beta_0\) , \(\beta_1\) are not the same as true values. \(\beta_0\) , \(\beta_1\) are random variables because of measurement error.
The residuals \(e_i\) are not the same as error \(\epsilon_i\).
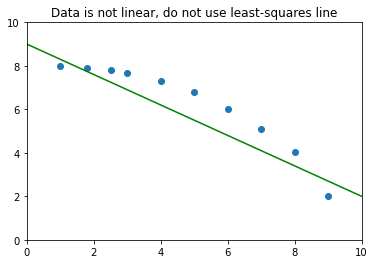
Do NOT extrapolate outside the range of the data.
Do NOT use the least-squares line when the data are not linear.
14.2.5. Measuring Goodness-of-Fit#
How well does the model explain the data?
Coefficient of determination:
Interpretation: proportion of the variance in \(y\) explained by regression.
See the textbook for the derivation of the \(r^2\) formula.