13.2. Standard Normal Distribution#
Further Reading: §4.12 in Navidi (2015)
13.2.1. Learning Objectives#
After studying this notebook, attending class, completing the home activities, and asking questions, you should be able to:
Understand standard normal distribution and why it is useful.
# load libraries
import numpy as np
import math
import matplotlib.pyplot as plt
13.2.2. Definition#
How could we answer the above question is we did not have access to Python? In other words, how did people do statistical analysis with simple calculators?
The core problem is that the integral for the cumulative distribution function (CDF) for the Gaussian (normal) distribution does not have an analytic solution.
This integral is calculated numerically. Virtually all statistics textbooks contain tables of computed values for the standard normal distribution, i.e., \(\mathcal{N}(0,1)\).
Here is an example.
You can convert any normal distribution to use these tables by standardizing:
Here \(z\) is sometimes called a \(z\)-score.
The values for expected number of defects (ev) and variance (var) are taken from the example in the last notebook.
# from Chap 11-01 (linked above)
ev = 0.64
var = 0.8504
# calculate z-score
z = (0.5 - ev)/(math.sqrt(var))
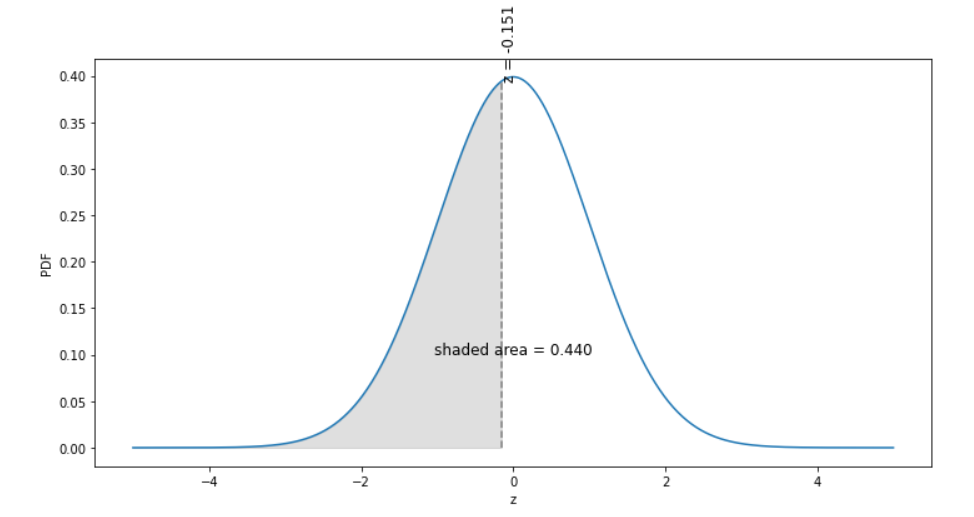
print(z)
-0.1518156033561421
We then look up the probability \(P(Z < -0.15) = 0.44\), which matches our result above. We will use Python in this class, but you should know these tables exist.
13.2.3. Exam Practice#
Show that if \(X \sim \mathcal{N}(\mu,\sigma^2)\) and \(Z = \frac{X - \mu}{\sigma}\) then \(Z \sim \mathcal{N}(0,1)\). Hint: Treat \(\mu\) and \(\sigma\) as constants.
Below is a graphical representation of the problem above.
lifetime = [3.2, 6.8, 4.2, 9.2, 11.2, 3.7, 2.9, 12.6, 6.4, 7.5, 8.6,
4.5, 3.0, 9.6, 1.5, 4.5, 6.3, 7.2, 8.5, 4.2, 6.3, 3.2, 5.0, 4.9, 6.6]
With these data, you can use statistics to ask two fundamental questions:
What is the population mean lifetime? (We want an uncertainty range.)
Does this sample of 25 catalysts have the manufacturer’s promised specifications?
# Make a histogram
plt.hist(lifetime)
plt.title("Histogram of Catalyst Lifetime")
plt.xlabel("Lifetime [hours]")
plt.ylabel("Frequency")
# Compute the mean and standard deviation
xbar = np.mean(lifetime)
s = np.std(lifetime)
print("Lifetime Average: {} hours".format(xbar))
print("Lifetime Standard Deviation: {} hours".format(s))
Lifetime Average: 6.064 hours
Lifetime Standard Deviation: 2.7185113573424697 hours
